Agent Skillsベストプラクティス:効果的なClaude Skillsを書くための完全ガイド
効果的なClaude Skillsを書くためのAgent Skillsベストプラクティス。簡潔さや段階的開示などのコア原則から、実行可能コードを使った高度なパターンまで、Agent Skillsベストプラクティスを学びましょう。

この記事は、Anthropicの公式ドキュメント「Skill Authoring Best Practices」に基づいています。
Agent Skillsベストプラクティスに従うことは、確実に動作するClaude Skillsを書くために不可欠です。このガイドでは、最も重要なAgent Skillsベストプラクティス、つまりClaudeが発見し効果的に使用できるClaude Skillsを書くための実践的な作成方法を解説します。
コアとなるAgent Skillsベストプラクティス
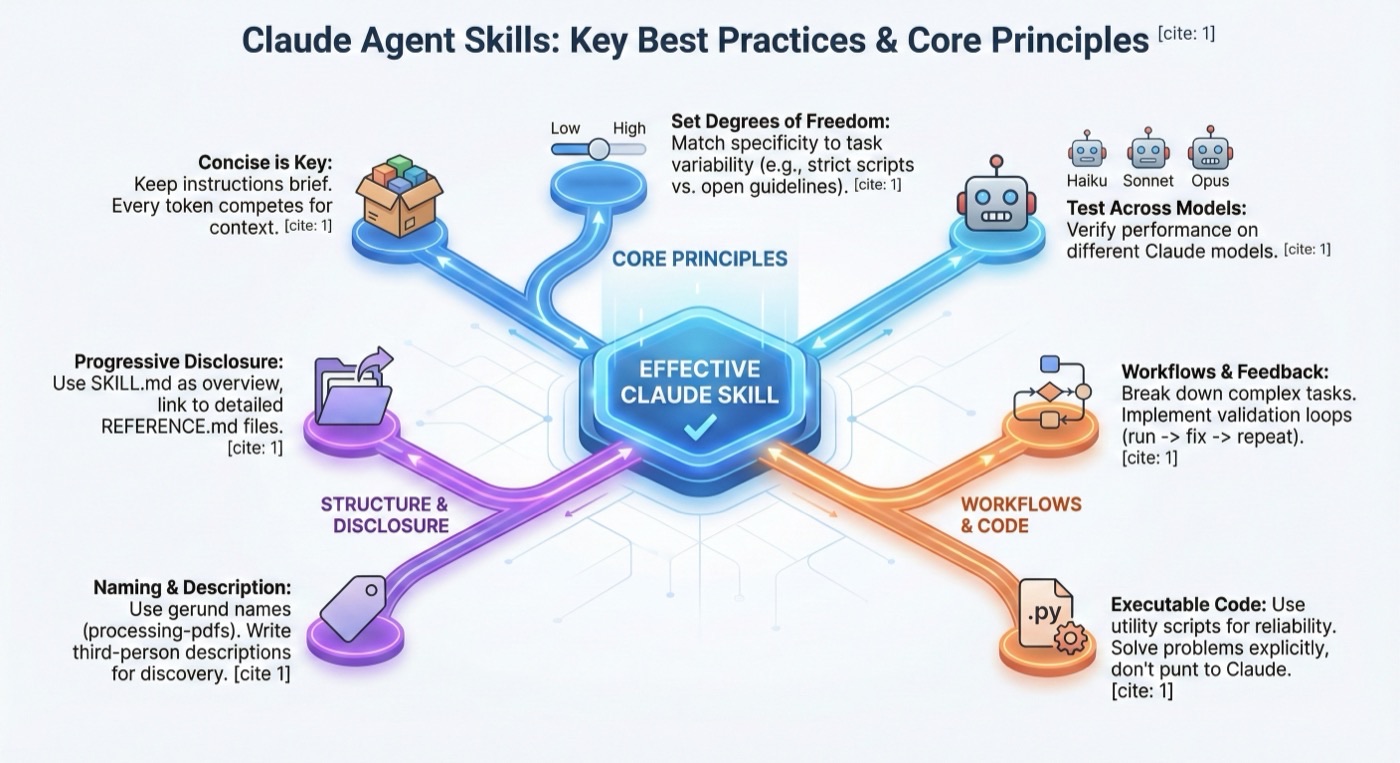
簡潔さが鍵
Agent Skillsベストプラクティスの中で最も重要なものの一つが簡潔さです。スキルは、システムプロンプト、会話履歴、他のスキルのメタデータ、そして実際のリクエストなど、Claudeが知る必要のあるすべてとコンテキストウィンドウを共有します。
すべてのトークンに即座のコストがかかるわけではありません。起動時には、すべてのスキルからメタデータ(名前と説明)のみがプリロードされます。Claudeは関連性が出てきた時にのみSKILL.mdを読み込みます。しかし、SKILL.mdの簡潔さは依然として重要です。Claudeがそれを読み込むと、すべてのトークンが会話履歴や他のコンテキストと競合するからです。
デフォルトの前提:Claudeはすでに非常に優秀です。Claudeがまだ持っていないコンテキストのみを追加してください。各情報を次のように問い直しましょう:
- 「Claudeにはこの説明が本当に必要か?」
- 「Claudeはこれを知っていると想定できるか?」
- 「この段落はトークンコストに見合うか?」
良い例(約50トークン):
## PDFテキストの抽出
テキスト抽出にはpdfplumberを使用:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
悪い例(約150トークン):
## PDFテキストの抽出
PDF(Portable Document Format)ファイルは、テキスト、画像、その他の
コンテンツを含む一般的なファイル形式です。PDFからテキストを抽出するには、
ライブラリを使用する必要があります。PDF処理に利用できるライブラリは多数
ありますが、pdfplumberが使いやすくほとんどのケースに対応できるため推奨します...
簡潔なバージョンは、ClaudeがPDFとは何か、ライブラリがどう動作するかを知っていることを前提としています。
適切な自由度を設定する
タスクの脆弱性と変動性に合わせた具体性のレベルを設定してください。
高い自由度(テキストベースの指示)— 複数のアプローチが有効な場合:
## コードレビュープロセス
1. コードの構造と組織を分析する
2. 潜在的なバグやエッジケースを確認する
3. 可読性と保守性の改善を提案する
4. プロジェクト規約への準拠を検証する
中程度の自由度(擬似コードやパラメータ付きスクリプト)— 推奨パターンがある場合:
## レポートの生成
このテンプレートを使用し、必要に応じてカスタマイズ:
```python
def generate_report(data, format="markdown", include_charts=True):
# データを処理
# 指定された形式で出力を生成
# オプションでビジュアライゼーションを含める
```
低い自由度(特定のスクリプト、パラメータなし or 少数)— 操作が脆弱な場合:
## データベースマイグレーション
このスクリプトを正確に実行:
```bash
python scripts/migrate.py --verify --backup
```
コマンドの変更やフラグの追加はしないでください。
Claudeを道を探索するロボットとして考えてください:
- 崖の上の狭い橋:安全な進み方は一つだけ。正確な指示を提供してください(低い自由度)。
- 広いフィールド:多くの道が成功に通じます。大まかな方向を示してください(高い自由度)。
使用予定のすべてのモデルでテストする
Skillsはモデルへの追加として機能するため、効果は基盤モデルに依存します:
- Claude Haiku(高速、経済的):Skillは十分なガイダンスを提供していますか?
- Claude Sonnet(バランス型):Skillは明確で効率的ですか?
- Claude Opus(強力な推論):Skillは過度な説明を避けていますか?
Opusで完璧に動作するものでも、Haikuにはより多くの詳細が必要になる場合があります。
スキル構造のためのAgent Skillsベストプラクティス
命名規則
スキル名には動名詞形(動詞+-ing)を使用します。nameフィールドには小文字、数字、ハイフンのみ使用できます。
良い例:
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentation
避けるべき名前:
- 曖昧な名前:
helper、utils、tools - 汎用的すぎる名前:
documents、data、files - 予約語:
anthropic-helper、claude-tools
効果的な説明文の書き方
descriptionフィールドはスキルの発見を可能にし、スキルが何をするか、いつ使用するかの両方を含める必要があります。
常に三人称で書いてください。 説明はシステムプロンプトに注入されます:
- 良い: "Processes Excel files and generates reports"
- 避ける: "I can help you process Excel files"
効果的な例:
# PDF処理
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
# Excel分析
description: Analyze Excel spreadsheets, create pivot tables, generate charts. Use when analyzing Excel files, spreadsheets, tabular data, or .xlsx files.
# Gitコミットヘルパー
description: Generate descriptive commit messages by analyzing git diffs. Use when the user asks for help writing commit messages or reviewing staged changes.
段階的開示パターン
SKILL.mdは概要として機能し、必要に応じてClaudeを詳細な資料に導きます。
- 最適なパフォーマンスのため、SKILL.md本文は500行以下に保つ
- この制限に近づいたら、コンテンツを別ファイルに分割する
パターン1:参照付きハイレベルガイド
---
name: pdf-processing
description: Extracts text and tables from PDF files, fills forms, and merges documents.
---
# PDF処理
## クイックスタート
pdfplumberでテキストを抽出:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## 高度な機能
**フォーム入力**:完全なガイドは[FORMS.md](FORMS.md)を参照
**APIリファレンス**:全メソッドは[REFERENCE.md](REFERENCE.md)を参照
**例**:一般的なパターンは[EXAMPLES.md](EXAMPLES.md)を参照
パターン2:ドメイン固有の構成
bigquery-skill/
├── SKILL.md(概要とナビゲーション)
└── reference/
├── finance.md(収益、請求メトリクス)
├── sales.md(商談、パイプライン)
├── product.md(API使用状況、機能)
└── marketing.md(キャンペーン、アトリビューション)
ユーザーが販売メトリクスについて質問した場合、Claudeは販売関連のスキーマのみを読み込めばよく、財務やマーケティングのデータは不要です。
パターン3:条件付き詳細
# DOCX処理
## ドキュメントの作成
新しいドキュメントにはdocx-jsを使用。[DOCX-JS.md](DOCX-JS.md)を参照。
## ドキュメントの編集
簡単な編集の場合は、XMLを直接変更。
**変更履歴の追跡**:[REDLINING.md](REDLINING.md)を参照
**OOXMLの詳細**:[OOXML.md](OOXML.md)を参照
深くネストされた参照を避ける
ファイルが他の参照ファイルから参照される場合、Claudeはファイルを部分的にしか読み取らない可能性があります。参照はSKILL.mdから1階層にとどめてください。
悪い例(深すぎる):
SKILL.md → advanced.md → details.md → 実際の情報
良い例(1階層):
SKILL.md → advanced.md
SKILL.md → reference.md
SKILL.md → examples.md
長いリファレンスファイルにはTOCを付ける
100行を超えるリファレンスファイルには、冒頭に目次を含めてください:
# APIリファレンス
## 目次
- 認証とセットアップ
- コアメソッド(作成、読み取り、更新、削除)
- 高度な機能(バッチ操作、Webhook)
- エラーハンドリングパターン
- コード例
ワークフローとフィードバックループのためのAgent Skillsベストプラクティス
複雑なタスクにはワークフローを使用する
複雑な操作を、チェックリスト付きの明確な順序のステップに分解します:
## リサーチ統合ワークフロー
このチェックリストをコピーして進捗を追跡:
```
リサーチの進捗:
- [ ] ステップ1:すべてのソースドキュメントを読む
- [ ] ステップ2:主要テーマを特定する
- [ ] ステップ3:主張を相互参照する
- [ ] ステップ4:構造化されたサマリーを作成する
- [ ] ステップ5:引用を検証する
```
**ステップ1:すべてのソースドキュメントを読む**
`sources/`ディレクトリの各ドキュメントをレビュー。主な論点をメモ。
**ステップ2:主要テーマを特定する**
ソース間のパターンを探す。繰り返し現れるテーマは何か?
**ステップ3:主張を相互参照する**
各主要な主張について、ソース資料に含まれていることを確認。
**ステップ4:構造化されたサマリーを作成する**
裏付けとなる証拠を含め、テーマ別に調査結果を整理。
**ステップ5:引用を検証する**
すべての主張が正しいソースを参照していることを確認。不完全な場合はステップ3に戻る。
フィードバックループを実装する
一般的なパターン:バリデーターを実行 -> エラーを修正 -> 繰り返し
## ドキュメント編集プロセス
1. `word/document.xml`を編集する
2. **即座にバリデーション**:`python ooxml/scripts/validate.py unpacked_dir/`
3. バリデーションが失敗した場合:
- エラーメッセージを注意深く確認
- XMLの問題を修正
- バリデーションを再実行
4. **バリデーションが通過してから次に進む**
5. 再構築:`python ooxml/scripts/pack.py unpacked_dir/ output.docx`
コンテンツガイドライン
時間に依存する情報を避ける
悪い例(いずれ誤りになる):
2025年8月以前にこれを行う場合は、旧APIを使用してください。
2025年8月以降は、新しいAPIを使用してください。
良い例(「旧パターン」セクションを使用):
## 現在の方法
v2 APIエンドポイントを使用:`api.example.com/v2/messages`
## 旧パターン
<details>
<summary>レガシーv1 API(2025-08に非推奨)</summary>
v1 APIは以下を使用:`api.example.com/v1/messages`
このエンドポイントはサポートされなくなりました。
</details>
一貫した用語を使用する
1つの用語を選択し、全体を通して使用してください:
- 良い例:常に「APIエンドポイント」、常に「フィールド」、常に「抽出」
- 悪い例:「APIエンドポイント」/「URL」/「APIルート」/「パス」を混在
一般的なパターン
テンプレートパターン
## レポート構造
常にこの正確なテンプレート構造を使用:
```markdown
# [分析タイトル]
## エグゼクティブサマリー
[主要な調査結果の1段落の概要]
## 主要な発見
- データを裏付けとする発見1
- データを裏付けとする発見2
## 推奨事項
1. 具体的で実行可能な推奨事項
2. 具体的で実行可能な推奨事項
```
例パターン
通常のプロンプティングと同様に、入力/出力のペアを提供します:
## コミットメッセージの形式
**例1:**
入力:JWTトークンによるユーザー認証を追加
出力:
```
feat(auth): implement JWT-based authentication
Add login endpoint and token validation middleware
```
**例2:**
入力:レポートで日付が正しく表示されないバグを修正
出力:
```
fix(reports): correct date formatting in timezone conversion
Use UTC timestamps consistently across report generation
```
条件付きワークフローパターン
## ドキュメント変更ワークフロー
1. 変更の種類を決定:
**新しいコンテンツの作成?** -> 以下の「作成ワークフロー」に従う
**既存コンテンツの編集?** -> 以下の「編集ワークフロー」に従う
2. 作成ワークフロー:
- docx-jsライブラリを使用
- ドキュメントをゼロから構築
- .docx形式でエクスポート
3. 編集ワークフロー:
- 既存ドキュメントを展開
- XMLを直接変更
- 各変更後にバリデーション
- 完了したら再パック
評価とイテレーションのためのAgent Skillsベストプラクティス
まず評価を構築する
最も重要なAgent Skillsベストプラクティスの一つ:広範なドキュメントを書く前に評価を作成してください。これにより、スキルが実際の問題を解決することが確認できます。
評価駆動開発:
- ギャップを特定する:Skillなしで代表的なタスクにClaudeを実行。具体的な失敗を記録
- 評価を作成する:これらのギャップをテストする3つのシナリオを構築
- ベースラインを確立する:Skillなしでのクロードのパフォーマンスを測定
- 最小限の指示を書く:ギャップに対応するのに十分なコンテンツのみ作成
- イテレーション:評価を実行し、ベースラインと比較し、改善
Claudeと反復的にSkillsを開発する
Claudeの1つのインスタンス(「Claude A」)と協力して、他のインスタンス(「Claude B」)が使用するSkillを作成します:
- Skillなしでタスクを完了する:Claude Aで問題を解決。繰り返し提供する情報に注目
- 再利用可能なパターンを特定する:タスク完了後、将来の類似タスクに役立つコンテキストを特定
- Claude AにSkillの作成を依頼する:Claudeモデルはネイティブにスキル形式を理解しています
- 簡潔さを確認する:Claudeが不必要な説明を追加していないか確認
- 類似タスクでテストする:関連するユースケースでClaude Bとスキルを使用
- 観察に基づいてイテレーション:Claude Bが苦戦した場合、具体的な内容を持ってClaude Aに戻る
上級:実行可能コードを持つSkills
解決する、丸投げしない
エラー条件をClaudeに丸投げするのではなく、処理してください:
# 良い例:エラーを明示的に処理
def process_file(path):
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
print(f"File {path} not found, creating default")
with open(path, "w") as f:
f.write("")
return ""
# 悪い例:Claudeに丸投げ
def process_file(path):
return open(path).read()
ユーティリティスクリプトを提供する
既製のスクリプトには、生成されたコードよりも利点があります:
- 生成コードより信頼性が高い
- トークンを節約(コンテキストにコードを含める必要がない)
- 時間を節約(コード生成が不要)
- 使用間の一貫性を確保
検証可能な中間出力を作成する
複雑なタスクには「計画-検証-実行」パターンを使用:
- 分析 -> 計画ファイルの作成 -> 計画の検証 -> 実行 -> 確認
これにより、エラーを早期に検出し、マシンで検証可能なバリデーションを提供し、明確なデバッグが可能になります。
避けるべきアンチパターン
- Windowsスタイルのパス:常にスラッシュを使用(
scripts/helper.py、scripts\helper.pyではない) - 選択肢が多すぎる:選択メニューではなく、エスケープハッチ付きのデフォルトアプローチを提供
- 曖昧な説明:「ドキュメントを支援」ではClaudeに有用な情報が伝わらない
- 深くネストされた参照:すべての参照をSKILL.mdから1階層に保つ
- マジックナンバー:設定値がその値である理由を文書化する
Agent Skillsベストプラクティスチェックリスト
コア品質
- 説明が具体的でキーワードを含んでいる
- 説明がスキルの機能と使用タイミングの両方を含んでいる
- SKILL.md本文が500行以下
- 追加の詳細は別ファイルに(必要な場合)
- 時間に依存する情報がない
- 全体を通して一貫した用語
- 例が具体的で抽象的でない
- ファイル参照が1階層
- 段階的開示が適切に使用されている
- ワークフローに明確なステップがある
コードとスクリプト
- スクリプトがClaudeに丸投げせず問題を解決する
- エラーハンドリングが明示的で有用
- マジック定数がない(すべての値に根拠あり)
- 必要なパッケージがリストされ利用可能であることが確認済み
- 重要な操作のためのバリデーション/検証ステップ
- 品質が重要なタスクにフィードバックループが含まれている
テスト
- 少なくとも3つの評価が作成されている
- Haiku、Sonnet、Opusでテスト済み
- 実際の使用シナリオでテスト済み
- チームのフィードバックが反映されている