Agent Skills 最佳实践:编写高效 Claude Skills 的完整指南
编写高效 Claude Skills 的 Agent Skills 最佳实践。从简洁性和渐进式披露等核心原则到包含可执行代码的高级模式,全面学习 Agent Skills 最佳实践。

本文基于 Anthropic 官方文档 Skill Authoring Best Practices。
遵循 Agent Skills 最佳实践对于编写可靠运行的 Claude Skills 至关重要。本指南涵盖了最重要的 Agent Skills 最佳实践——帮助您做出实际的编写决策,让 Claude 能够有效地发现和使用您编写的 Claude Skills。
核心 Agent Skills 最佳实践
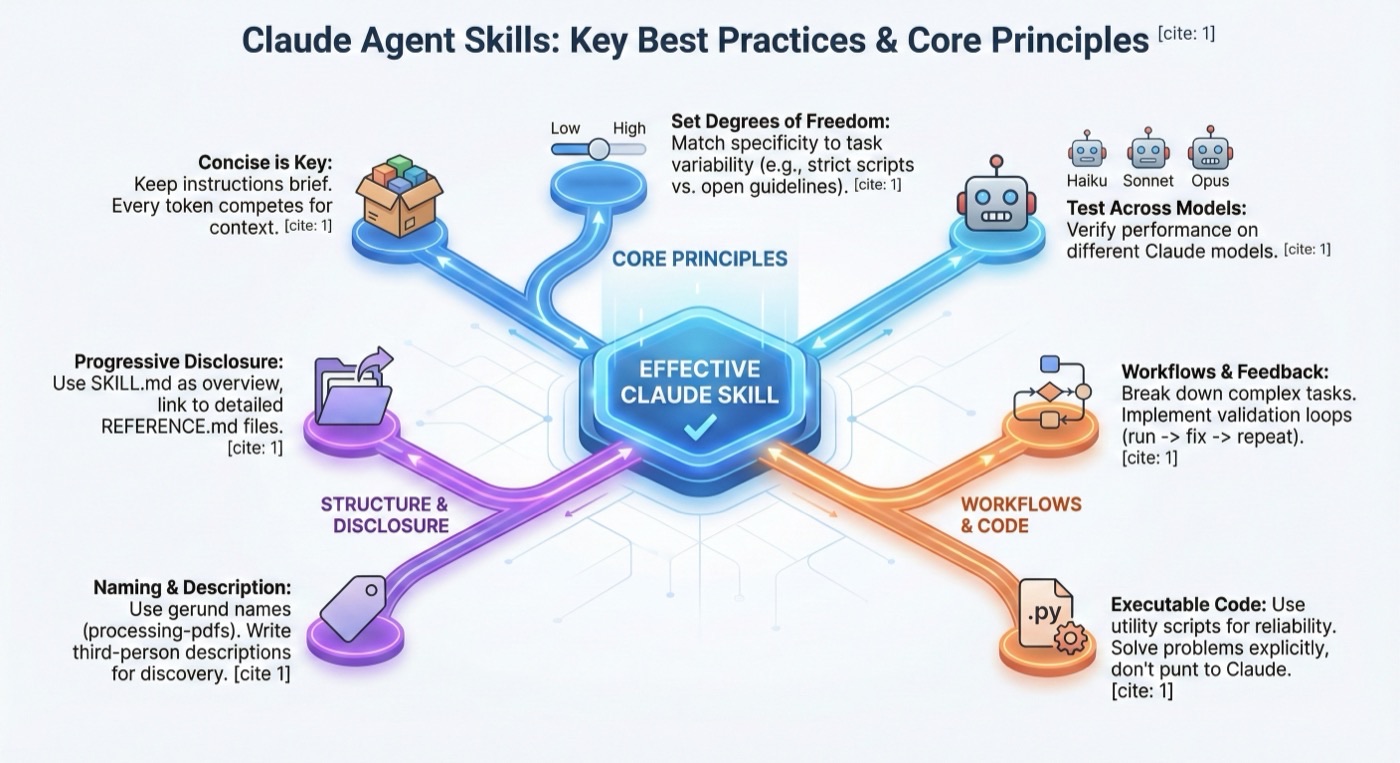
简洁是关键
Agent Skills 最佳实践中最重要的一条就是简洁。您的 Skill 与 Claude 需要了解的所有其他内容共享上下文窗口,包括系统提示、对话历史、其他 Skills 的元数据以及您的实际请求。
并非 Skill 中的每个 token 都有即时成本。在启动时,只有所有 Skills 的元数据(名称和描述)会被预加载。Claude 仅在 Skill 变得相关时才读取 SKILL.md。然而,SKILL.md 的简洁性仍然很重要:一旦 Claude 加载它,每个 token 都会与对话历史和其他上下文竞争。
默认假设:Claude 已经非常聪明。只添加 Claude 不已知的上下文。审视每条信息:
- "Claude 真的需要这个解释吗?"
- "我能假设 Claude 知道这个吗?"
- "这段内容值得它的 token 成本吗?"
好的示例(约 50 个 token):
## 提取 PDF 文本
使用 pdfplumber 进行文本提取:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
差的示例(约 150 个 token):
## 提取 PDF 文本
PDF(便携式文档格式)文件是一种常见的文件格式,包含文本、图像和其他内容。
要从 PDF 中提取文本,您需要使用一个库。有很多可用的 PDF 处理库,
但我们推荐 pdfplumber,因为它易于使用并且能处理大多数情况...
简洁版本假设 Claude 知道什么是 PDF 以及库是如何工作的。
设置适当的自由度
根据任务的脆弱性和可变性匹配具体程度。
高自由度(文本指令)——当多种方法都有效时使用:
## 代码审查流程
1. 分析代码结构和组织
2. 检查潜在的错误或边界情况
3. 建议改善可读性和可维护性
4. 验证是否遵循项目约定
中自由度(伪代码或带参数的脚本)——当存在首选模式时使用:
## 生成报告
使用此模板并根据需要自定义:
```python
def generate_report(data, format="markdown", include_charts=True):
# 处理数据
# 以指定格式生成输出
# 可选包含可视化
```
低自由度(特定脚本,很少或没有参数)——当操作脆弱时使用:
## 数据库迁移
精确运行此脚本:
```bash
python scripts/migrate.py --verify --backup
```
不要修改命令或添加额外的标志。
将 Claude 想象成一个探索路径的机器人:
- 有悬崖的窄桥:只有一条安全前进的路。提供精确指令(低自由度)。
- 开阔地:许多路径都能成功。给出大致方向(高自由度)。
用所有计划使用的模型测试
Skills 作为模型的附加组件,因此有效性取决于底层模型:
- Claude Haiku(快速、经济):Skill 是否提供了足够的指导?
- Claude Sonnet(平衡):Skill 是否清晰高效?
- Claude Opus(强大推理):Skill 是否避免了过度解释?
对 Opus 完美运行的内容可能需要为 Haiku 提供更多细节。
Skill 结构的 Agent Skills 最佳实践
命名规范
使用动名词形式(动词 + -ing)作为 Skill 名称。name 字段必须仅使用小写字母、数字和连字符。
好的示例:
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentation
避免:
- 模糊的名称:
helper、utils、tools - 过于笼统:
documents、data、files - 保留词:
anthropic-helper、claude-tools
编写有效的描述
description 字段实现 Skill 的发现功能,应该包含 Skill 做什么以及何时使用它。
始终使用第三人称。 描述会被注入到系统提示中:
- 好的: "Processes Excel files and generates reports"
- 避免: "I can help you process Excel files"
有效示例:
# PDF 处理
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
# Excel 分析
description: Analyze Excel spreadsheets, create pivot tables, generate charts. Use when analyzing Excel files, spreadsheets, tabular data, or .xlsx files.
# Git 提交助手
description: Generate descriptive commit messages by analyzing git diffs. Use when the user asks for help writing commit messages or reviewing staged changes.
渐进式披露模式
SKILL.md 作为概览,引导 Claude 在需要时查看详细资料。
- SKILL.md 正文保持在 500 行以内以获得最佳性能
- 接近此限制时将内容拆分到单独文件中
模式 1:带引用的高级指南
---
name: pdf-processing
description: Extracts text and tables from PDF files, fills forms, and merges documents.
---
# PDF 处理
## 快速开始
使用 pdfplumber 提取文本:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## 高级功能
**表单填写**:参见 [FORMS.md](FORMS.md) 获取完整指南
**API 参考**:参见 [REFERENCE.md](REFERENCE.md) 获取所有方法
**示例**:参见 [EXAMPLES.md](EXAMPLES.md) 获取常用模式
模式 2:按领域组织
bigquery-skill/
├── SKILL.md(概览和导航)
└── reference/
├── finance.md(收入、计费指标)
├── sales.md(商机、管线)
├── product.md(API 使用、功能)
└── marketing.md(活动、归因)
当用户询问销售指标时,Claude 只需要读取销售相关的模式,不需要读取财务或营销数据。
模式 3:条件性细节
# DOCX 处理
## 创建文档
使用 docx-js 创建新文档。参见 [DOCX-JS.md](DOCX-JS.md)。
## 编辑文档
对于简单编辑,直接修改 XML。
**用于跟踪变更**:参见 [REDLINING.md](REDLINING.md)
**OOXML 详情**:参见 [OOXML.md](OOXML.md)
避免深层嵌套引用
当文件从其他被引用的文件中引用时,Claude 可能只会部分读取。保持引用从 SKILL.md 出发只有一层深度。
差的(太深):
SKILL.md → advanced.md → details.md → 实际信息
好的(一层):
SKILL.md → advanced.md
SKILL.md → reference.md
SKILL.md → examples.md
用目录结构化较长的参考文件
对于超过 100 行的参考文件,在顶部包含目录:
# API 参考
## 目录
- 认证和设置
- 核心方法(创建、读取、更新、删除)
- 高级功能(批量操作、Webhooks)
- 错误处理模式
- 代码示例
工作流和反馈循环的 Agent Skills 最佳实践
对复杂任务使用工作流
将复杂操作分解为清晰的、有检查清单的顺序步骤:
## 研究综合工作流
复制此检查清单并跟踪您的进度:
```
研究进度:
- [ ] 步骤 1:阅读所有源文档
- [ ] 步骤 2:识别关键主题
- [ ] 步骤 3:交叉引用声明
- [ ] 步骤 4:创建结构化摘要
- [ ] 步骤 5:验证引用
```
**步骤 1:阅读所有源文档**
查阅 `sources/` 目录中的每个文档。记录主要论点。
**步骤 2:识别关键主题**
在各源之间寻找模式。哪些主题反复出现?
**步骤 3:交叉引用声明**
对每个主要声明,验证它在源材料中出现。
**步骤 4:创建结构化摘要**
按主题组织发现,附带支持证据。
**步骤 5:验证引用**
检查每个声明是否引用了正确的来源。如果不完整,返回步骤 3。
实现反馈循环
常见模式:运行验证器 -> 修复错误 -> 重复
## 文档编辑流程
1. 在 `word/document.xml` 中进行编辑
2. **立即验证**:`python ooxml/scripts/validate.py unpacked_dir/`
3. 如果验证失败:
- 仔细查看错误信息
- 修复 XML 中的问题
- 再次运行验证
4. **仅在验证通过后继续**
5. 重建:`python ooxml/scripts/pack.py unpacked_dir/ output.docx`
内容指南
避免时效性信息
差的(会过时):
如果你在 2025 年 8 月之前做这件事,使用旧 API。
2025 年 8 月之后,使用新 API。
好的(使用"旧模式"部分):
## 当前方法
使用 v2 API 端点:`api.example.com/v2/messages`
## 旧模式
<details>
<summary>旧版 v1 API(2025-08 弃用)</summary>
v1 API 使用:`api.example.com/v1/messages`
此端点不再受支持。
</details>
使用一致的术语
选择一个术语并在全文中一致使用:
- 好的:始终使用 "API endpoint"、始终使用 "field"、始终使用 "extract"
- 差的:混用 "API endpoint" / "URL" / "API route" / "path"
常见模式
模板模式
## 报告结构
始终使用此精确的模板结构:
```markdown
# [分析标题]
## 执行摘要
[关键发现的一段概述]
## 关键发现
- 发现 1 附支持数据
- 发现 2 附支持数据
## 建议
1. 具体可操作的建议
2. 具体可操作的建议
```
示例模式
提供输入/输出对,就像在常规提示中一样:
## 提交信息格式
**示例 1:**
输入:Added user authentication with JWT tokens
输出:
```
feat(auth): implement JWT-based authentication
Add login endpoint and token validation middleware
```
**示例 2:**
输入:Fixed bug where dates displayed incorrectly in reports
输出:
```
fix(reports): correct date formatting in timezone conversion
Use UTC timestamps consistently across report generation
```
条件工作流模式
## 文档修改工作流
1. 确定修改类型:
**创建新内容?** -> 按照下面的"创建工作流"
**编辑已有内容?** -> 按照下面的"编辑工作流"
2. 创建工作流:
- 使用 docx-js 库
- 从头构建文档
- 导出为 .docx 格式
3. 编辑工作流:
- 解压已有文档
- 直接修改 XML
- 每次更改后验证
- 完成后重新打包
评估与迭代的 Agent Skills 最佳实践
先建立评估
最关键的 Agent Skills 最佳实践之一:在编写大量文档之前先创建评估。这确保您的 Skill 解决的是真实问题。
评估驱动开发:
- 识别差距:在没有 Skill 的情况下让 Claude 执行代表性任务。记录具体的失败
- 创建评估:构建三个测试这些差距的场景
- 建立基线:衡量没有 Skill 时 Claude 的表现
- 编写最小指令:创建刚好足够解决差距的内容
- 迭代:执行评估,与基线比较,然后改进
与 Claude 迭代开发 Skills
与一个 Claude 实例("Claude A")合作创建一个供其他实例("Claude B")使用的 Skill:
- 在没有 Skill 的情况下完成任务:与 Claude A 一起解决问题。注意您反复提供了哪些信息。
- 识别可复用的模式:任务完成后,识别哪些上下文对类似的未来任务有用。
- 请 Claude A 创建 Skill:Claude 模型原生理解 Skill 格式。
- 审查简洁性:检查 Claude 是否添加了不必要的解释。
- 在类似任务上测试:将 Skill 与 Claude B 在相关用例上使用。
- 根据观察迭代:如果 Claude B 遇到困难,带着具体问题回到 Claude A。
高级:带可执行代码的 Skills
解决问题,而不是推卸
处理错误条件而不是推卸给 Claude:
# 好的:显式处理错误
def process_file(path):
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
print(f"File {path} not found, creating default")
with open(path, "w") as f:
f.write("")
return ""
# 差的:推卸给 Claude
def process_file(path):
return open(path).read()
提供实用脚本
预制脚本相比生成的代码有优势:
- 比生成的代码更可靠
- 节省 token(无需在上下文中包含代码)
- 节省时间(无需代码生成)
- 确保跨使用的一致性
创建可验证的中间输出
对于复杂任务,使用"计划-验证-执行"模式:
- 分析 -> 创建计划文件 -> 验证计划 -> 执行 -> 验证
这可以尽早发现错误,提供机器可验证的验证,并支持清晰的调试。
应避免的反模式
- Windows 风格路径:始终使用正斜杠(
scripts/helper.py,而不是scripts\helper.py) - 选项太多:提供一个默认方法和一个逃生出口,而不是一个选择菜单
- 模糊的描述:"Helps with documents" 告诉 Claude 没有任何有用信息
- 深层嵌套引用:保持所有引用从 SKILL.md 只有一层深度
- 魔法数字:记录配置值为什么是这样的
Agent Skills 最佳实践检查清单
核心质量
- 描述具体且包含关键术语
- 描述包括 Skill 做什么和何时使用
- SKILL.md 正文少于 500 行
- 额外细节在单独的文件中(如需要)
- 无时效性信息
- 全文术语一致
- 示例具体,而非抽象
- 文件引用一层深度
- 适当使用渐进式披露
- 工作流有清晰的步骤
代码和脚本
- 脚本解决问题而不是推卸给 Claude
- 错误处理明确且有帮助
- 无魔法常量(所有值有依据)
- 列出所需的包并验证可用
- 关键操作有验证/确认步骤
- 质量关键任务包含反馈循环
测试
- 至少创建三个评估
- 在 Haiku、Sonnet 和 Opus 上测试
- 用真实使用场景测试
- 纳入团队反馈